知名浏览器对DOCTYPE模式的选择机制
text/html内容的模式选择取决于doctype嗅探(doctype sniffing,本文后面有讨论)。在IE8中,模式也取决于其他因素。然而在IE8的默认情况下,那些不在微软提供黑名单上的非局域网(non- intranet)站点的模式取决于文档类型。
怪癖模式中,为了避免“破坏”那些根据在20世纪90年代末流行的实践创作的页面,浏览器违反了现代的Web格式规范。不同的浏览器实现了不同的怪癖行为。Internet Explorer6、7和8中,怪癖模式有效地冻结在IE5.5 。其他浏览器中,怪癖模式是对准标准模式的少量偏移。
irefox、Safari、Chrome、Opera(从7.5开始)和IE8也有个叫“准标准模式”的模式,它按照传统的做法来实现表格单元格的垂直尺寸而不是严格的遵照CSS2规范。Mac IE5、Windows IE6和7、Opera7.5以前版本和Konqueror无需准标准模式,因为它们至少没有在各自的标准模式下严格遵循CSS2规范来实现表格单元格垂直尺寸。实际上,它们的标准模式更接近Mozilla的准标准模式而不是Mozilla的标准模式。
IE8有个模式主要是冻结了IE7标准模式的副本。其他浏览器没有像这样的模式,且该模式也未被HTML5指定。
基于WebKit的Nokia S60 浏览器中,application/xhtml+xml HTTP内容类型不能触发XML模式,因为在移动的围墙花园(mobile walled gardens)中关注点是对不规范内容的兼容性。(旧式的“移动浏览器”无法使用真正的XML解析器,因为不规范内容已被标记为XML。)
某些引擎拥有的模式与Web内容无关。为了完整性,它们仅仅在这里被提到。Opera有个WML2.0模式。Leopard上的WebKit有个用于旧式Dashboard widgets的特定模式。
text/html的模式主要是影响CSS布局asp学习。例如,表格不继承样式是个怪癖。在某些浏览器的怪癖模式下,盒模型(box model)变成IE5.5的盒模型。本文档没有列举出所有的布局怪癖。
XML模式中,选择器有不同的区分大小写行为。此外,用于HTML body元素的特有规则不能应用在那些没有实现最新CSS2.1改变的较旧版本的浏览器。
也有一些怪癖影响HTML和CSS的解析且会导致符合标准的网页被错误解析。怪癖布局决定了这些怪癖是否开启。无论如何,了解怪癖模式和标准模式在CSS布局和解析(非HTML解析)上的主要异同是非常重要的。
一些人错误地把标准模式称为“严格解析模式(strict parsing mode)”,其让人误解了浏览器强制执行HTML语法规则和用浏览器评估标记的正确性。情况并非如此。即使当标准模式布局生效时如何修改asp代码,浏览器依旧会做标签杂烩汤(tag soup,)修正工作。(在2000年Netscape6发布前,Mozilla的确有用于强制执行HTML语法规则的解析模式。这些模式和现有的Web内容不兼容而被遗弃。)
另一个常见的误解是关于XHTML解析的。通常认为用XHTML doctype得到不同的解析。其实并非如此,内容类型是text/html的XHTML文档所用解析器和HTML文档的是同一个。目前浏览器在意的是文档类型为text/html的XHTML仅是“撒面包丁的标签杂烩汤(tag soup with croutons)”(到处是额外的斜线)。
虽然怪癖模式主要是关于CSS的,但也有一些是关于脚本的。例如,Firefox的怪癖模式中,HTML id 属性像在IE一样建立了全局脚本作用域的对象引用。IE8中关于脚本的影响比其他浏览器更值得关注。
XML模式中,某些DOM API的行为彻底不同,因为XML的DOM API行为被定义时不兼容HTML的行为。
现代浏览器使用doctype嗅探来决定text/html文档的引擎模式。这意味着模式的选择是基于HTML文档开始的文档类型声明(或缺少)。(这不适于使用XML文档类型的文档。)
文档类型声明(doctype)是SGML的语法伪造,SGML是个旧式的标记框架,HTML5之前的HTML就是依据其定义的。HTML4.01规范中,文档类型声明描述的是HTML的版本信息。尽管名字叫“文档类型声明”且HTML 4.01规范所描述的是关于“版本信息”,文档类型声明并不适用把SGML或XML文档分类为特定类型的文档,即使它看起来像是(因为名字)。(更多内容在附录中)
HTML4.01规范和ISO 8879(SGML)都没有说关于使用文档类型声明作为引擎模式转换的任何事情。doctype嗅探是基于观察,在doctype嗅探被设计时,绝大部分的怪癖文档既没有文档类型声明也没有引用旧的DTD。HTML5接受这个事实,且定义了text/html中doctype作为唯一的模式转换。
典型的预HTML5(pre-HTML5)文档类型声明包含(被空白分开)“<!DOCTYPE”字符串,根元素(“html”)的通用标识符, “PUBLIC”字符串,处于引号中的DTD公共标识符,同一DTD的可能系统标识符(URL)和字符 “>”。文档类型声明位于文档的根元素开始标签之前。
我不推荐任何的XHTML doctype,因为XHTML被用作text/html被认为是有害的。无论如何,如果你选择使用XHTML doctype,请注意XML声明会使IE6(但不是IE7!)触发怪癖模式。
对application/xhtml+xml的简单指南是绝不使用doctype。该方式下的网页不是“严格一致”的XHMTL1.0,但这并不重要。(请看后面的附录)
IE8有4种模式:IE5.5怪癖模式、IE7标准模式、IE8 准标准模式 和IE8标准模式。模式的选择取决于来自几个方面的数据:doctype、meta元素、HTTP头、来自微软的定期下载数据、局域网域、用户所做设置、局域网管理员所做设置、父框架的模式(如果有)和地址栏兼容视图按钮被用户触发。(对于嵌入该引擎的其他应用,模式也取决于嵌入的应用。)
在 X-UA-Compatible 情况下,IE8的行为和其他浏览器完全不同。想看本页的附录PDFPNG格式的流程图。
不幸的是,没有 X-UA-Compatible的HTTP头或meta标签,即使使用了合适的doctype,IE8让用户无意间使页面从IE8的标准模式降到IE7模式,这是一种仿线标准模式。更糟糕的是,局域网管理员也可以这么做。微软也可以把你所用的所有域名到列入黑名单。
下面的简单指南是针对已经有doctype在其他浏览器触发标准模式或者准标准模式的新的text/html文档如何选择X-UA-Compatible HTTP头或meta标签的:
doctype嗅探是用签杂烩汤似的方法解决一个标签杂烩汤问题。doctype嗅探是在HTML4和CSS2规范发布后设计的一种试探方法,它从文档中区分出过时文档以符合其作者可能期望的行为。
偶尔有人建议在XML上使用doctype嗅探来调度不同的处理、识别正在使用的词汇表或激活特性。这是个坏主意。调度和词汇表识别应该是基于名字空间的,而特性激活应该是基于明确的处理指令或元素。
良构(well-formedness)的整个思想是介绍允许XML的无DTD解析,且推广无doctype文档。在正式情况下,两个XML文档有相同的规范形式且应用不同地处理它们(且不同之处并非因为没有选择处理外部实体),这个应用或许被破坏了。在实践情况下,如果两个XML文档导致同样的内容被报告(qnames忽略)给SAX2内容处理器且应用不同地处理文档,这个应用或者被破坏了。考虑到作为 Web作者无法相信每个人都会使用解决额外实体的XMLprocessor来解析其页面(即使一些浏览器看起来这样做,因为它们会映射一定公共的标识符到一个有删节的定义实体的DTD),插入doctype到XML中用于Web是毫无意义的且通常会导致货运崇拜(cargo cultish)习惯。(您仍然使用W3C验证器的DTD覆盖功能来对一个DTD进行验证,虽然W3C验证器会说结果仅仅是暂时有效。或更好的是,你可以用放宽NG验证,它不会污染模式引用的文档。)为了嗅探而要求doctype是非常愚蠢的,即使那是在HTML实践中的解决方法。
我不担心HTML和SGML构造相同的参数的原因是Web浏览器不会使用真正的SGML解析器去解析HTML,所以我认为伪装成SGML进行处理是没有用的。无论如何,如果你还不相信,请看W. Eliot Kimber关于此事的文章 comp.text.sgml
下表中,怪癖模式、标准模式和准标准分别表示为Q、S和A。当浏览器仅有两种模式时,如果表格单元格的行高和Mozilla的标准模式表现一致时,标准模式标记为“S”,如果表格单元格的行高和Mozilla的准标准模式表现一致时,则标记为“A”。
本表的目的并不是说表中所有的doctype都是新建页面的合理选择。本表的目的是为了展示我的推荐是依据什么样的数据。
从表中可见,Opera的doctype嗅探正由规律的从类似IE向类似Mozilla转变,虽然Opera9.5和9.6在倒退的路上。同时,Opera怪癖模式的布局行为已从仿效IE6的怪癖模式转换到Mozilla的怪癖模式。
HTTP/1.1 协议规定的 HTTP 请求方法有 OPTIONS、GET、HEAD、POST、PUT、DELETE、TRACE、CONNECT 这几种。其中 POST 一般用来向服务端提交数据,本文主要讨论 POST 提交数据的几种方式。我们知道,HTTP 协议是以 ASCII...查看详情
HTML的发展历史:HTML英语意思是Hypertext Marked Language,即超文本标记语言,是一种用来制作超文本文档的简单标记语言。HTML是由WEB的发明者Tim Berners-Lee和同事nolly于1990年...查看详情
一、<div></div>和<span></span>1.<div></div>标签<div></div>标签可定义文档中的分区或节(division/section),从而把文档分割...查看详情
简介最近在做大作业的时候需要做一个弹幕播放器。借鉴了一下别人的源码自己重新实现了一个,演示如下主要的功能有发送弹幕设置弹幕的颜色,速度和类型显示弹幕已知缺陷:不能全屏canvas没有做自适应没有自定义播放器控件没有根据播放时间显示相应的弹幕弹幕不能实现悬停...查看详情
name指定标签的名称。格式<input type="text" name="username" />应用场景①form表单:name可作为转递给服务器表单列表的变量名;如上面的传到服务器的名称为:username=text的...查看详情
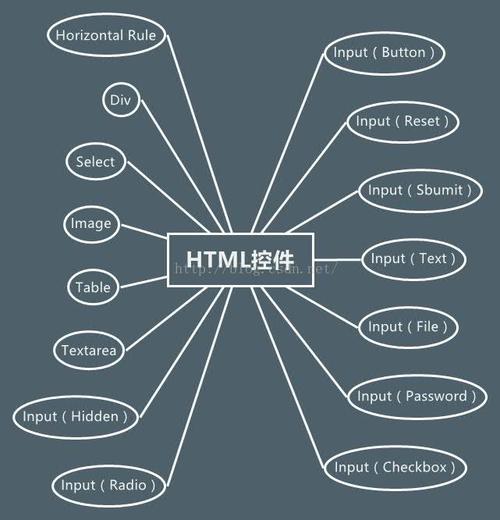
<input>标签<input> 标签用于搜集用户信息。type属性根据不同的 type 属性值,输入字段拥有很多种形式。可以是文本字段、复选框、掩码后的文本控件、单选按钮、按钮等等。text:文本区域readonly属性:是否只读。passwor...查看详情
简介meta标签是HTML语言HEAD区的一个辅助性标签。meta常用于定义页面的说明,关键字,最后修改日期,和其它的元数据。这些元数据将服务于浏览器(如何布局或重载页面),搜索引擎和其它网络服务。mata 标签包含全局属性(查看详情
前言meta是html语言head区的一个辅助性标签。也许你认为这些代码可有可无。其实如果你能够用好meta标签,会给你带来意想不到的效果,meta标签的作用有:搜索引擎优化(SEO),定义页面使用语言,自动刷新并指向新的页面,实现网页转换时的动态效果,控制页面缓冲,网页定级评价...查看详情
XML/HTML Code复制内容到剪贴板 <inputid="username"name="username"type="text"placeholder=&...查看详情